|
Showing: limited to 100 messages
|
| Captcha service broken |
| (3 responses) |
millerjw4 |
2020-02-11 06:47 |
|
Hello,
Our production instance of LabKey is having an issue with the Captcha service on the registration page. This production instance is on 19.3, and this error does not happen on 19.2.
I see the following stacktrace from a 500 error when LabKey calls the captcha service:
HTTP Status 500 – Internal Server Error
Type Exception Report
Message Servlet execution threw an exception
Description The server encountered an unexpected condition that prevented it from fulfilling the request.
Exception
javax.servlet.ServletException: Servlet execution threw an exception
org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53)
org.labkey.api.module.ModuleLoader.doFilter(ModuleLoader.java:1226)
org.labkey.api.security.AuthFilter.doFilter(AuthFilter.java:215)
org.labkey.core.filters.SetCharacterEncodingFilter.doFilter(SetCharacterEncodingFilter.java:118)
Root Cause
java.lang.NoClassDefFoundError: Could not initialize class java.awt.image.BufferedImage
com.google.code.kaptcha.text.impl.DefaultWordRenderer.renderWord(DefaultWordRenderer.java:37)
com.google.code.kaptcha.impl.DefaultKaptcha.createImage(DefaultKaptcha.java:43)
com.google.code.kaptcha.servlet.KaptchaServlet.doGet(KaptchaServlet.java:84)
javax.servlet.http.HttpServlet.service(HttpServlet.java:634)
javax.servlet.http.HttpServlet.service(HttpServlet.java:741)
org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53)
org.labkey.api.module.ModuleLoader.doFilter(ModuleLoader.java:1226)
org.labkey.api.security.AuthFilter.doFilter(AuthFilter.java:215)
org.labkey.core.filters.SetCharacterEncodingFilter.doFilter(SetCharacterEncodingFilter.java:118)
Note The full stack trace of the root cause is available in the server logs.
Apache Tomcat/9.0.27
|
 kaptcha.PNG kaptcha.PNG |
| view message |
| Displaying additional sample fields in the assay data upload interfaces |
| (1 response) |
dvlieghe |
2020-01-15 08:30 |
|
Hello,
I'm in a Labkey Biologics trial, but I guess my question is general to the platform.
In the assay data upload 'interfaces' ('Upload File', 'Copy-and-Paste Data' and 'Enter Data Into Grid') of the assay runs, only Sample Id is used to characterize the samples. Is it possible to expose other Sample fields in these interfaces (even from Data Classes linked via a Lookup)? If you upload assay data via the Manage Samples menu, Sample Id's are nicely pre-populated, but only in the 'Enter Data Into Grid' interface. It would be nice if that could be extended: more fields, and also in the Excel template.
For a regular end user, computer generated Id's are very uninformative, which can lead to errors when entering/uploading data. So I was wondering whether it is possible to provide more context in the assay data upload process.
Best,
Dominique
|
| view message |
| Sharing/joining datasets between folders |
| (3 responses) |
Karen Bates |
2019-11-05 11:53 |
|
Hello,
I would like to join tables from data sets across sub-folders within a project. The below link describes a folder filter option when selecting the Grid option on a data set to customize a grid with a table from another folder, but I'm not seeing that option when I open any of my grids. Is that feature only available in certain folder types or for select data sets?
https://www.labkey.org/Documentation/wiki-page.view?name=filterByFolder
Is the Shared Project folder the best way to share a data set across sub-folders?
Thank you!
Karen
|
| view message |
| Dataset with 2 or more Additional Key Column |
| (1 response) |
Chichero |
2019-10-21 07:22 |
|
Multiple Additional Key Columns in a Dataset
Is it possible to create a dataset in a study with 2 or more Additional Key Columns. As I understand in the Edit Definitions mode one can choose only 1 column as a Key Column.
If it is not possible with datasets are there any solutions to this issue?
|
| view message |
| Recompute Timepoints did not work |
| (1 response) |
hadiwika |
2019-10-11 13:09 |
|
Hello,
I have negative timepoints on my study and 1 day duration and these are not ideal for our study settings. Therefore, I changed the start Date of the overall project and also change the Default Timepoint Duration to 365. However when I click Update and then RECOMPUTE TIMEPOINTS, the timepoints didn't change to follow the new timepoint settings.
I didn't receive any error message so I didn't know what went wrong. I hope you can shed some light on this problem.
Regards,
Wahyu
|
| view message |
| Help with Study Reload |
| (1 response) |
Karen Bates |
2019-10-11 07:54 |
|
Hello,
I'm new to LabKey and attempting to reload a study but I'm not sure on the steps in between the export and import of the reload. I exported the existing study to the pipeline and I have three excels that are reloads of the existing datasets that I need to import. How do I map them to the study? Do they need to be saved somewhere specific so they are captured in the reload process and in a certain file type?
I have reviewed the Export, Import, and Reload Study documentation pages but still cannot quite connect the steps.
Thank you!
|
| view message |
| Export data without lookup, remove all columns from grid view option |
| (1 response) |
millerjw4 |
2019-10-08 08:10 |
|
Hello,
I was advised to submit support tickets by developers for the following items at the LabKey user conference, but I am unable to do this as I am a community user. I will post them here instead and hope they reach the right people.
Option to export data without lookups
Currently, when data using lookups in a LabKey grid view is exported to xlsx/tsv, the data is exported with the lookup value, and there is no option to recover the non-lookup value. It would be nice if this were made available as an option, as the script exports (R/Python/etc) export the raw data without lookup
Option to create a grid view starting with no columns
Currently, you have to base a new grid view on a dataset in the study schema, and if you are only interested in creating a report on a few columns (ie age/sex from demographics, measure 1 from instrument A), then it is a pain to have to remove all columns manually from whichever dataset you choose to base the view on.
It would be nice if there was an option to either:
- Make a grid view not based on a particular dataset
- Remove all columns from the 'selected fields' area after choosing 'customize grid'
Thank you for your help.
|
| view message |
| Configuration Error Detected at LabKey Server Startup |
| (1 response) |
cheryl mendonca |
2019-09-24 05:57 |
|
I use a database of a study which I have always been able to log in to enter data all this time. But today it is showing an error message saying 'Configuration Error Detected at LabKey Server Startup' when I try to open the link to the database. I have attached the screen shot of how it looks when I try to open the database link.
|
 Doc2.docx Doc2.docx |
| view message |
| Exporting Data without Lookup? |
| (1 response) |
millerjw4 |
2019-08-08 14:04 |
|
Hello,
I am currently trying to create a study in LabKey. The study data is exported from a number of REDCap projects, which use integer codes for categorical fields. I am uploading the data in this integer-coded form, then using lookup tables (1: 'Male', 2: 'Female' 3: 'Other', etc) to display the text values for these fields in the data grid in an effort to make the data more readable. However, I would like for users to be able to export the data in its original, integer-coded form for use in analysis software. When I explore LabKey's export options, it seems to only be able to export the text lookup, without the ability to go back to the original integer codes. I'm not sure if I'm missing something, but it would be really nice to have that functionality without needing to rely on some external transformation to restore the original codes from REDCap.
Thanks for any assistance,
Jonathan
|
| view message |
| ELISA Module Customization: Sample dilutions, using non-linear curve fit for calibration curves |
| (1 response) |
Sarah Bertrand |
2019-08-06 14:12 |
|
We are running edition 19.10 of the LabKey Server.
We are currently trying to upload a few standard ELISA assays onto our LabKey server and have run into a few problems:
-
There does not appear to be a way to change the calibration curve fit to anything but linear. Is there a setting I am missing or a work-around to fit other kinds of curves (i.e. 4 parameter curve fit) for concentration interpolation?
--Is there a way to calculate EC50 in any assay modules and track across time in any other assay modules? I have attempted to modify a Luminex assay, but I am unable to load our data file
-
We have several dilutions per sample on our ELISA plates. I tried to account for this by adding 'other' labels for the well assignments, but I do not see a way to incorporate this into the assay setup. I essentially need a column multiplying the interpolated concentration by the dilution factor. Additionally, I would like to be able to average the 4 wells (2 duplicates*2 dilutions) to get the average concentration and the error associated with the mean.
Is there a way to post-process concentrations in the ELISA module or some kind of work around for it?
Thank you!
|
| view message |
| Files in fileset not updating |
| (1 response) |
David Owen |
2019-07-12 09:13 |
|
I'm running LabKey Server 19.1.1. When I manually add files or directories from the command line to the site-level file root they don't appear on LabKey. What am I missing?
|
| view message |
| NAB assay QC report in Results Details |
| (1 response) |
Floris van Waes |
2019-07-11 07:11 |
|
Dear Labkey,
We are having some trouble with your NAB assays. When performing a NAB assay on our uniQure NAb server and we want to export "Run Details" in the form of a PDF (Print) the QC data that is excluded does not appear anymore in the PDF. This while in the "Run Details" when data is excluded using the "Review/QC Data" option the excluded wells are marked red. This does not appear in the PDF.
Because for the purpose of QA reports we need to show which wells are excluded, is it possible to have these visualized in the PDF?
|
| view message |
| Error in Site Users - Community Edition 19.1 - Can't view users list |
| (1 response) |
Gina M Scott |
2019-07-02 12:59 |
|
Version 19.1
We get an error when we click on Site Users -
only shows one user and it is not the logged in user and displays this error:
An unexpected error occurred
Could not convert '-4,-1' to an integer
Details:
org.apache.commons.beanutils.ConversionException: Could not convert '-4,-1' to an integer
at org.labkey.api.data.ConvertHelper$_IntegerConverter.convert(ConvertHelper.java:606)
at org.apache.commons.beanutils.ConvertUtilsBean.convert(ConvertUtilsBean.java:428)
at org.apache.commons.beanutils.ConvertUtils.convert(ConvertUtils.java:217)
at org.labkey.api.data.MultiValuedRenderContext.get(MultiValuedRenderContext.java:116)
at org.labkey.api.data.DataColumn.getValue(DataColumn.java:243)
at org.labkey.api.data.DataColumn.renderGridCellContents(DataColumn.java:324)
at org.labkey.api.data.DisplayColumnDecorator.renderGridCellContents(DisplayColumnDecorator.java:51)
at org.labkey.api.data.MultiValuedDisplayColumn.renderGridCellContents(MultiValuedDisplayColumn.java:139)
at org.labkey.api.data.DisplayColumn.renderGridDataCell(DisplayColumn.java:980)
at org.labkey.api.data.DataRegion.renderTableRow(DataRegion.java:1642)
at org.labkey.api.data.DataRegion.renderTableContents(DataRegion.java:1601)
at org.labkey.api.data.DataRegion.renderTableContent(DataRegion.java:1173)
at org.labkey.api.data.DataRegion.renderCenterContent(DataRegion.java:1214)
at org.labkey.api.data.DataRegion._renderDataTableNew(DataRegion.java:1188)
at org.labkey.api.data.DataRegion._renderTableNew(DataRegion.java:1077)
at org.labkey.api.data.DataRegion.renderTable(DataRegion.java:980)
at org.labkey.api.data.DataRegion.render(DataRegion.java:2518)
at org.labkey.api.view.GridView._renderDataRegion(GridView.java:64)
at org.labkey.api.view.DataView.renderView(DataView.java:211)
at org.labkey.api.view.DataView.renderView(DataView.java:58)
at org.labkey.api.view.WebPartView.renderView(WebPartView.java:476)
at org.labkey.api.view.WebPartView.renderInternal(WebPartView.java:371)
at org.labkey.api.view.HttpView.render(HttpView.java:132)
at org.labkey.api.view.HttpView.render(HttpView.java:117)
at org.labkey.api.view.HttpView.include(HttpView.java:512)
at org.labkey.api.view.HttpView.include(HttpView.java:489)
at org.labkey.api.query.QueryView.renderDataRegion(QueryView.java:2231)
at org.labkey.api.query.QueryView.renderView(QueryView.java:1977)
at org.labkey.api.view.WebPartView.renderInternal(WebPartView.java:371)
at org.labkey.api.view.HttpView.render(HttpView.java:132)
at org.labkey.api.view.HttpView.render(HttpView.java:117)
at org.labkey.api.view.HttpView.include(HttpView.java:512)
at org.labkey.api.view.HttpView.include(HttpView.java:489)
at org.labkey.api.view.HttpView.include(HttpView.java:477)
at org.labkey.api.view.VBox.renderView(VBox.java:74)
at org.labkey.api.view.WebPartView.renderInternal(WebPartView.java:371)
at org.labkey.api.view.HttpView.render(HttpView.java:132)
at org.labkey.api.view.HttpView.render(HttpView.java:117)
at org.labkey.api.view.HttpView.include(HttpView.java:512)
at org.labkey.api.view.HttpView.include(HttpView.java:489)
at org.labkey.jsp.compiled.org.labkey.core.view.template.bootstrap.body_jsp._jspService(body_jsp.java:259)
at org.labkey.api.view.JspView.renderView(JspView.java:170)
at org.labkey.api.view.WebPartView.renderInternal(WebPartView.java:371)
at org.labkey.api.view.HttpView.render(HttpView.java:132)
at org.labkey.api.view.HttpView.render(HttpView.java:117)
at org.labkey.api.view.HttpView.include(HttpView.java:512)
at org.labkey.api.view.HttpView.include(HttpView.java:489)
at org.labkey.jsp.compiled.org.labkey.core.view.template.bootstrap.pageTemplate_jsp._jspService(pageTemplate_jsp.java:214)
at org.labkey.api.view.JspView.renderView(JspView.java:170)
at org.labkey.api.view.WebPartView.renderInternal(WebPartView.java:371)
at org.labkey.api.view.HttpView.render(HttpView.java:132)
at org.labkey.api.view.HttpView.render(HttpView.java:117)
at org.labkey.api.action.SpringActionController.renderInTemplate(SpringActionController.java:615)
at org.labkey.api.action.SpringActionController.handleRequest(SpringActionController.java:495)
at org.labkey.api.module.DefaultModule.dispatch(DefaultModule.java:1265)
at org.labkey.api.view.ViewServlet._service(ViewServlet.java:204)
at org.labkey.api.view.ViewServlet.service(ViewServlet.java:131)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:741)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:231)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.labkey.api.data.TransactionFilter.doFilter(TransactionFilter.java:38)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.labkey.api.module.ModuleLoader.doFilter(ModuleLoader.java:1220)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.labkey.api.security.AuthFilter.doFilter(AuthFilter.java:215)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.labkey.core.filters.SetCharacterEncodingFilter.doFilter(SetCharacterEncodingFilter.java:118)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:200)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96)
at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:490)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:139)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92)
at org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:668)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:74)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:343)
at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:408)
at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66)
at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:834)
at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1415)
at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.base/java.lang.Thread.run(Thread.java:835)
Caused by: java.lang.NumberFormatException: Character , is neither a decimal digit number, decimal point, nor "e" notation exponential mark.
at java.base/java.math.BigDecimal.<init>(BigDecimal.java:518)
at java.base/java.math.BigDecimal.<init>(BigDecimal.java:401)
at java.base/java.math.BigDecimal.<init>(BigDecimal.java:834)
at org.labkey.api.data.ConvertHelper$_IntegerConverter.convert(ConvertHelper.java:595)
... 91 more
request attributes
LABKEY.OriginalURL = http://labkey.nrel.gov/labkey/user-showUsers.view?returnUrl=%2Flabkey%2Fadmin-showAdmin.view%3F
LABKEY.StartTime = 1562084593824
LABKEY.action = showUsers
org.springframework.web.servlet.DispatcherServlet.CONTEXT = Root WebApplicationContext: startup date [Sat Jun 15 01:43:22 MDT 2019]; parent: Root WebApplicationContext
LABKEY.controller = user
LABKEY.Counter = 0
X-LABKEY-CSRF = acfbfcfe610545c7d52c6743d6e51b1f
LABKEY.container =
LABKEY.RequestURL = /labkey/user-showUsers.view?returnUrl=%2Flabkey%2Fadmin-showAdmin.view%3F
LABKEY.OriginalURLHelper = /labkey/user-showUsers.view?returnUrl=%2Flabkey%2Fadmin-showAdmin.view%3F
core schema database configuration
Server URL jdbc:jtds:sqlserver://ignsql-listener.nrel.gov:1433/Labkey
Product Name Microsoft SQL Server
Product Version 13.00.5292
Driver Name jTDS Type 4 JDBC Driver for MS SQL Server and Sybase
Driver Version 1.3.1
|
| view message |
| Manual upgrade errors from LabKey18.2-60915.94 to LabKey19.1.1-63156.2 |
| (1 response) |
vipin |
2019-05-20 05:45 |
|
Dear LabKey team,
Thank you for the providing the LabKey server. We are using the community edition LabKey server version number LabKey18.2-60915.94. It was running smoothly with the sample registrations and other relevant tasks for our use.
Recently we upgraded the instance from LabKey18.2-60915.94 to LabKey19.1.1-63156.2. With the upgrade, we didn't find any errors. We have performed the manual upgrade with the provided script manual-upgrade.sh from the distribution.
When we start the instance now with the version LabKey19.1.1-63156.2, I have been experiencing following problems which were not there in my old version of LabKey18.2-60915.94.
Features missing in the new release/or may be this is not rendered properly to my upgrade:
- There are no parent child relationship representation with the sample which I selected. This was working nicely before.
- New Sample registration fails with the error message RowId or LSID required to get the Sample set materials
(ERROR ReadOnlyApiAction 2019-05-20 14:45:11,146 ttps-jsse-nio-443-exec-3 : ApiAction exception:
org.labkey.api.query.QueryUpdateServiceException: Either RowId or LSID is required to get Sample Set Material.)
I m attaching two screen shots from my instance and I am not sure whether this is something to do with the database schema. I don't know how to do this and let me know if you have seen this before.
I am happy to provide the stdout message from my upgrade script run as well. I am not seeing much information from the log message as well.
Thank you very much in advance,
Vipin
|
| parent-child-relation.png labkey-registration.png |
| view message |
| LabKey 19.1.1 updates |
|
avital |
2019-04-11 09:28 |
|
|
|
| view message |
| Upgrade to 19.1 and Java upgrade on Linux |
| (11 responses) |
tvaisar |
2019-03-25 15:12 |
|
Hi,
I am trying to upgrade our Labkey Server to 19.1 and have to upgrade Java in the process (from Java 8). Per this page, https://www.labkey.com/the-java-shake-up-what-it-means-to-labkey-and-you/, downloaded OpenJDK12 with HotSpot VM from https://adoptopenjdk.net/. Installed and added the PATHs as references in the Labkey Server manual installation instructions. However, although it appears that the correct java is running (java --version shows version 12), I cannot get the Labkey Server started. From Tomcat log (catalina.out) it appears that it cannot create java virtual machine. Error: Could not create the Java Virtual Machine.
Also on Tomcat shutdown.sh the same message appears.
Tomas
UW
|
| view message |
| "No data to show"/zero rows in dataset when I navigate to its grid from the Dataset web part, but I can select rows from the same dataset |
| (3 responses) |
jmb |
2019-03-05 14:08 |
|
In my study I have multiple datasets that are reloaded regularly from a study archive. After one such reload last week, the datasets in my study appear to be empty when I navigate to their grids from the Datasets webpart. E.g. I have a dataset called Enrollment. If I create a Datasets web part, and then select the Enrollment dataset, I see an empty grid with no data to show. However I know the data successfully loaded, because if I query 'select * from Enrollment' I see all the expected rows. What might be causing this? As far as I can see, the URL parameter passed to the query when accessing Enrollment from the Datasets webpart is correct (URL is ../labkey/NDDdb/study-dataset.view?datasetId=5001, and 5001 is the correct datasetId for the Enrollment dataset).
|
| view message |
| Log- or ongoing-style data |
| (4 responses) |
sadams7703 |
2019-02-28 16:45 |
|
Hi,
I am trying to build out a study the has been going on for some time. So I am uploading data.
The study has a Participant ID - Visit Number structure for most data.
However, some data were collected without a Visit Number but only have a Participant ID and a date. In addition, there are multiple entries for each Participant ID (and also Participant ID-date).
An example is a "concomitant medication log" in which the Paticipant ID, Start Date, Stop Date, and Med Name are recorded in each row (a "log-book") regardless of study visits.
Another example is a "vital status follow up log" in which each phone call or contact with a participant is recorded for years after the last formal study visits. So each row is Participant ID, Date of Call, Vital Status.
Is there a way I can integrate these data into a study with a Participant ID-Visit Number structure?
I have been trying with a General Assay but having no success, as it is demanding a Visit Number when I copy over the data from the assay to the study. Is there a way around this?
Or do I need to assign dummy Visit Numbers or use some other work around?
Thanks,
Scott
|
| view message |
| Tutorial - Excel import not working when Timezone CEST |
| (3 responses) |
nicolas fenwick |
2019-02-28 01:42 |
|
Hi LabKey team,
I am going through the tutorials and noticed that the import of the Excel dataset is not working in my local instance of Labkey (which I find really amazing by the way, congratulations).
I live in France (CEST timezone).
The error message is attached.
As I was debugging I noticed that CEST was not correctly handled in DateUtil.java
resolveDatePartEnum(s) (line 297) returns null as CEST is not in the TimeZone list (line 252):
z("UTC"),gmt("UTC"),ut("UTC"),utc("UTC"),
// North America
est(-5*60),edt(-4*60),cst(-6*60),cdt(-5*60),mst(-7*60),mdt(-6*60),pst(-8*60),pdt(-7*60),
// Europe
cet("CET"), wet("WET")
;
Now if you did add it, TimeZone.java translates it automatically to "CET" which causes another issue in DateUtil.java (line 292):
return (null != entry && StringUtils.startsWithIgnoreCase(entry.getKey(), s)) ? entry.getValue() : null;
this returns null and another process starts to try and recognise CEST thanks to TimeZone.getTimeZone(s).
Unfortunately TimeZone.getTimeZone(s) does not recognise CEST and translates it to GST.
resolveDatePartEnum(String s) will return null which will raise an exception.
That issue was raised by Christine Rousseau:
https://www.labkey.org/e545879c-dd5d-1032-a3b5-e5ac4624956c/announcements-thread.view?entityId=414cafa3-6e2f-1035-b86e-fe851e083e48&_docid=thread%3A414cafa3-6e2f-1035-b86e-fe851e083e48
I am not sure whether it has been fixed but I thought I would let you know about my investigations before it gets lost. I hope that helps.
Cheers,
Nico
|
| LabkeyErrorImport.JPG |
| view message |
| Scrolling Issue on 18.2 |
| (4 responses) |
slatour |
2018-11-30 10:10 |
|
Dear LabKey team,
One of our users pointed out after upgrading to 18.2 the following issue:
"when we are scrolling through a repository with many files, the repository will start flashing and stop scrolling for a bit. I tried to take a screen shot but that resets the screen."
Is this a possible bug?
Please advise.
Thanks in advance.
|
| view message |
| *Problem with Aliases* |
| (1 response) |
slatour |
2018-11-27 07:01 |
|
Hi LabKey team,
I have created the following tables in a study:
- Alias mapping table
- Demographics table
- General dataset with participant IDs
These are the steps I took:
- Turned on the alias settings within the "Manage Study" page.
- imported my general dataset with lab IDs
Results:
- General dataset with lab IDs successful were transformed to the alias IDs as expected.
However, as per our change management procedures I tested how to remove aliases and found the following:
Results (2):
- I went to manage study view and removed aliases from the study
- The general dataset did not revert back to the labID, and in fact kept the alias
This is a major concern for us as we had know way to revert back to LabIds, and we are concerned that the database was overwritten with the alias ID. Furthermore, I even tried to manually change back the ID to no avail - It seems as though the study would not refresh.
Please advise.
Thanks,
|
| view message |
| Problem with copying Expression Matrix assay run data to a study |
| (5 responses) |
jytian |
2018-11-20 18:52 |
|
Hi LabKey Server support: Thank you for your help in advance.
I have an "Expression Matrix" assay, and I have successfully imported the "sample information" file, "feature annotation" file and "gene expression matrix" file into the assay. The assay run result is a table of 4 columns: "Value", "Probe Id", "Sample Id" and "Run". I want to copy this table to a Study. When doing so, LabKey asks me to provide "Participant ID" and "Visit ID" for each row. My problem is: I have tens of thousands of rows and there is no way I can manually enter these values for all rows. There must be a way to get these two fields automatically mapped, but I have tried all I could and read LabKey documents I could find and I cannot find a way of doing so. The LabKey tutorials on this subject apply to many other assay types but not to "Expression Matrix" assay type. I tried to add a "ParticipantVisitResolver" field in the assay's design (the batch property) and LabKey doesn't accept it. I customized the grid view of the run data (the table I want to copy to the study) by adding the "Participant ID" and "Visit ID" columns to it (they are linked to the sample id in the sample set so I can add them to the table), but LabKey doesn't recognize them and still asks me to provide values for those two fields. Please give me a clue on how to automatically map these two fields. Your help is greatly appreciated!
Regards
Joann
|
| view message |
| Indexing of large lists |
| (3 responses) |
phains |
2018-11-19 20:44 |
|
I have an installation of LK Community Edition running on Win server 2012.
I am uploading some very large lists (up to 1.7 million lines). Part of my goal in uploading these lists is that I can search them all at the same time for their contents using the LK “search” function. The problem is, not all the lists seem to be getting indexed, what I assume takes place, to allow for rapid searching.
When I first loaded the lists, searching returned no results. Leaving them over the weekend, most of the smaller lists now return matches with the same search terms that failed previously. Hence my theory about the lists getting indexed in some way. These smaller lists only contain ~200,000-400,000 lines.
So far, after about a week, the larger lists still do not return any matches, even when I know they contain the search term. I can filter each list individually using the search term directly in that column of the list, it works fine and is quite fast.
Are there any limits on list size and what will work with the generic LK search function? Is there something I can do to get this working on my system with the larger lists?
Thanks for any suggestions,
Peter
|
| view message |
| Issue Tracker Assigned User List Issue |
| (1 response) |
slatour |
2018-11-19 13:28 |
|
Dear LabKey Admin,
During User acceptance testing we noticed that once we add a project group of users to the editor role within a folder, the issue tracker is not updated. Our issue tracker is currently set up to populate the assigned users list from "All Project Users", yet when we add a new project group these users are not reflected in the list.
Please advise.
Cheers,
Sara
|
| view message |
| I have downloaded the labkey server but still cannot create a project. What else do I need to do? |
| (1 response) |
pjjester |
2018-11-02 08:40 |
|
|
|
| view message |
| Delete large list |
| (3 responses) |
wdduncan |
2018-10-29 15:04 |
|
I have a list on my system that says it has 999,999 records. When I try to delete it using the list manager or the folder manager, the application becomes unresponsive. I that another way to manually delete the records?
|
| view message |
| Chose administrators of moderator review page? and other Qs |
| (3 responses) |
Nat |
2018-10-25 16:32 |
|
Hi,
We are creating a job's board on the Skyline website and have a few questions:
I have set up a test board with the permissions for the messages as follows:
"readers" set to "guests"
"Message board contributors" set to "all site users". I have set the "default settings for Messages " to "no email" (we don't need to spam our whole list every time we get a posting).
So to read the listings, you don't have to have an account. But to post you do.
So that's the settings:
Questions:
* was is the benefit of assigning "Author" instead of "Message Board Contributor".
* Secondly, I have the job board set up with "moderator review" -- where do I assign accounts to be "moderators" -- it seems to say that "administrators" will be invited to approve the posting. I just want a few people that will "moderate" not every admin we have set up on the Skyline site.
* when I look at the postings, there's an option to "respond" -- as this is a job board -- I'd rather not give the option to reply to the posting, just email or call the employer directly. Is there a way to turn off the "respond" feature.
* is there a way to also turn off the "delete post" option for authors? I'd rather just have people edit it as "filled"
Thanks!
-- Nat
|
| view message |
| Automate linking of participant ids to flow cytometry analysis |
| (2 responses) |
wdduncan |
2018-10-23 16:07 |
|
We are importing a number of flow cytometry analyses into LabKey. We need to link the analyses to the participants. We can import the flow data into the study. But then we have to manually associate each participant with the flow analysis.
I've attached screenshots.
Is is possible to automate this?
We are running version 18.2 on a Windows 10 server.
Thanks,
Bill
|
| image001.jpg image002.jpg |
| view message |
| Create embedded chart for 18.2 |
| (2 responses) |
wdduncan |
2018-10-23 15:58 |
|
|
|
| view message |
| integrating datasets beyond variable lookup .. |
| (1 response) |
torgriml |
2018-10-16 14:05 |
|
A question from a freshman (version 15 community edition user): My data are registered in separate datasets according to visit/sequence.
Is there an easy way to feed these separate datasets into one main dataset (which includes all visits) real-time ?
|
| view message |
| 'Copy' files from one Files directory to another? |
| (1 response) |
Nat |
2018-10-16 12:19 |
|
Hi,
Quick question: is it possible to 'copy' files from one @files directory within LabKey to another. The toolbar certainly allows for 'moving' files but how about copying?
Seems like just modifying the "move" function to add a checkbox allowing "copying" would be an easy fix?
Thanks !
-- Nat
|
| view message |
| Error: Failed to locate comet/tandem. |
| (6 responses) |
hyang04 |
2018-10-11 09:06 |
|
Hi LabKey team,
I was trying to use the MS2 module in our internal LabKey server, and was not able to run comet or tandem. The error message I got is posted below.
= = = = =
2018 23:38:44,413 ERROR: Failed to locate tandem. Use the site pipeline tools settings to specify where it can be found. (Currently 'D:\Program Files\LabKey Server\bin')
Caused by: java.io.FileNotFoundException: Failed to locate tandem. Use the site pipeline tools settings to specify where it can be found. (Currently 'D:\Program Files\LabKey Server\bin')
= = = = =
The folder D:\Program Files\LabKey Server\bin' does exist on our server computer, but there is no tandem or comet executable file under folder "D:\Program Files\LabKey Server\bin". I attached the screenshot image of that folder. That all the files we can see now.
I wonder if our setting is correct. Could you help us to set up the MS2 module?
Thank you
Best,
Han-Yin
|
| server_folder.jpg |
| view message |
| Prompt to re-login but account not recognized? |
| (1 response) |
esakbar |
2018-10-11 07:29 |
|
I've been trying to login to the Zika Open-Research Portal (https://zika.labkey.com/project/home/begin.view?) and even though I have a LabKey account it's not letting me log in? I'm clearly logged in today but it won't let me log in there. It doesn't even seem to acknowledge that I have an account since I click on "forgot password" but never receive a password reset e-mail for it.
I'm not sure what happened since I was able to log in before.
|
| view message |
| help setting up file uploads/downloads to an external service |
| (1 response) |
angel kennedy |
2018-09-17 23:50 |
|
Hi I'm hoping to get some advice on the best way to upload and download files to an external server via Labkey.
Here's the situation...
We are planning to upload large image datasets to labkey along with other trial data etc so that they can be shared amongst users.
We've been allocated a cloud based server with a small amount of storage on it that we can run LabKey from.
We've also been allocated a large amount of storage space on a separate system (it's for storage only) that at present cannot be mounted as a drive to our VM server.
We can however copy files between the 2 using pshell (a python based program that contains simple commands for file management).
I pretty new to LabKey and I haven't set up a file server before but the options I'm considering are
(a) set up a different file service that uses pshell beind the scenes to access the storage space and place a url link to the files in this service within rows of labkey.
(b) use trigger scripts within Labkey to trigger a pshell script to copy or retrieve files as needed.
How I think (b) might work
uploads: Use the normal labkey file upload system to upload the files onto the labkey server. A trigger script would be used to run a pshell script to move the files to the remote location. If it is not possible to attatch a trigger script to the file upload section then one could be attached to the “create” and “update” calls when an appropriate entry is created or edited in a table associating the files with patient data. The table would have a file link as per the “Linking Data Records with External Files” tutorial. A field indicating whether the file was locally stored or not (“local storage”) would be present and when the file transfer was complete the script could update this field to indicate that the file was no longer stored locally.
Downloads: The table mentioned above would also have a field indicating that the file should be retrieved. This would default to false. When a user wanted to download the file they would need to edit the row and change this field to true. Upon update a trigger script would then fetch the file and change the “local storage” field to true indicating that the user could now use the link to download the file.
One issue is how to know when to remove the file from local storage again. This could perhaps occurr after a specific interval or daily. At any rate it seems like it will be problematic.
My actual questions...
- Can anyone suggest a good (hopefully easy to set up and use) file-server that could run pshell under the hood to access files?
- Is my plan for getting labkey to use pshell reasonable? Is there a better and/or simpler method of doing this? Ideally I would like the process to be as user frinedly as possible and I feel the plan I've outlined above is not ideal in that respect.
thanks
|
| view message |
| Update documentation for folder-level email template customization |
| (1 response) |
Nat |
2018-09-11 14:52 |
|
Hi,
Was trying to remember how to get to folder level customization of email templates and searched and found this link:
https://www.labkey.org/Documentation/Archive/18.2/wiki-page.view?name=customEmail&_docid=wiki%3A8003189b-69a8-1036-a854-8d7bb845bfdb
This is the old way I used to customize an email template.
Now I think there are several ways of getting there without having to edit URLs. The way I figured out was to click on the "messages" container for a folder and click on "admin" from the triangle icon to the right. This brings up the "Customize Messages" page and at the bottom, I clicked on the link for "Customize Template for this Folder" which sends me to the "Customize Folder-Level Email" where I can make changes to the folder's email template.
Since this is a little cryptic to remember -- especially when one rarely needs to update customizing folder-level templates ... would be nice to have the documentation updated.
-- Nat
|
| view message |
| Non-responsive UI element (Knitr Options) when trying to create a new R report? |
| (2 responses) |
olnerdybastid |
2018-08-21 14:32 |
|
I am trying to learn a bit about creating R reports by following the tutorial here https://www.labkey.org/Documentation/wiki-page.view?name=knitr. But I can't get past the step 'Specify which source to process with knitr. Under knitr Options, select HTML or Markdown', because when I'm on the Source tab, the 'expand node' icon on the Knitr Options bar is not functional. Nothing happens when I click the arrow to expand the node, so I can't view the Knitr config options to complete the rest of the steps. Any ideas why this is happening?
I'm on LabKey v18.1, and this is reproducible on every browser I've tried (Safari, Chrome, & Firefox, all on a Mac).
|
| view message |
| Prompts to re-login when switching between subfolders |
| (2 responses) |
olnerdybastid |
2018-08-07 06:33 |
|
I have a LabKey project containing three subfolders (which may themselves contain subfolders later on). Each of these folders inherits its permissions from the parent folder, in which I'm the administrator. When I start a new session (fresh browser, cache cleared), I need to log in to each of these folders separately (meaning the first time I navigate to each of these subfolders I get another login prompt). Is this due to a misconfiguration of my security settings, and if so how should they be set so that I can log in only once and navigate freely between subfolders?
|
| view message |
| Audit Log access to Non-Admin |
| (1 response) |
leyshock |
2018-08-06 15:33 |
|
Per the recommendation here: https://www.labkey.org/Documentation/wiki-page.view?name=audits I've assigned the role "See Audit Log Events" to a particular user on our system, and saved the changes. Going to Admin --> Site --> Site Permissions, I confirmed that the assignment 'stuck'.
Now, impersonating that user, I cannot find the audit trail. Am I correct in thinking that it'd be accessed for this user the same way an Administrator would access it, namely, Admin --> Site --> Admin Console --> Admin Console Links --> Audit Log?
Or is there another route to the Audit Log that's typically used for users with the "See Audit Log Events" role?
Chrome on Mac, LabKey 17.3
Thanks, Patrick
|
| view message |
| How do we ignore existing rows in a dataset when “importing bulk data” and import only new rows |
| (1 response) |
Chidi |
2018-08-01 06:33 |
|
Hi support team,
How do we ignore existing rows in a dataset when “importing bulk data” and import only new rows?
This feature exists when importing data in a sample set. Attached is a screenshot of the feature, and I highlighted the one that are important to us.
Is there a way we can include the feature to our datasets? This will be helpful because we can download an excel sheet, add new rows on our computer, and import the excel sheet successfully into labkey portal without getting a blank or an error message saying “some rows already exist in the dataset on Labkey”.
Thank you very much.
|
| Screen Shot 2018-08-01 at 9.24.36 AM.png |
| view message |
| Displaying all the users information that have access to a sub folder |
| (1 response) |
Chidi |
2018-08-01 06:08 |
|
Hello,
For every subfolder, is there a way we can show the contact information of all the users or people who have access to it?
We tried using the contact web part (also called “Project Contacts”) and the information we followed can be found here https://www.labkey.org/Documentation/wiki-page.view?name=contacts. By default, the contact web part show all the users in the project. Our project has multiple subfolders and every user only has access to some folders. Is there a way we can make this web part show only the users in a given subfolder?
Thank you very much.
|
| view message |
| paid vs Community version |
| (3 responses) |
WayneH |
2018-07-24 12:04 |
|
Hi support team...
Just had to reach out regarding this question of differences in functionality in paid vs free version (would be a great bit of info to put on the website perhaps).
I reached out to Bernie but didn't get a response. I include a copy of the email here but basically it relates to concerns here about not necessarily much making use of the 'paid' modules(for now anyway) and particularly our middleware team wanting us to run the latest version of the tool..
Can you provide some information on this or direct me to a resource discussing this detail..? It will certainly help this discussion that periodically arises.
Thanks
WH
|
| view message |
| Missing experiment numbers |
| (1 response) |
emohr |
2018-07-23 13:04 |
|
I have an experiment list in my lab notebook and it has randomly skipped numbers when a new experiment was added. I start with experiment 1, experiment 2, then skipped experiment 3-4 when I selected "add new experiment". It's also skipped some in the teens. Are these experiments in limbo land somewhere and I can add them back in? How can I find them and add them back into the line up?
|
| view message |
| ETL to become premium feature in v18.3 |
| (1 response) |
Will Holtz |
2018-07-18 09:42 |
|
Hi,
Today I received an email notification about the release of LabKey v18.2 and at near the bottom of the message was a note that in v18.3, "ETL module will become a premium feature." Does this mean the existing ETL functionality will be removed from the community edition? Or will there be new ETL functionality added that will be premium only and the community edition will retain the current level of ETL functionality?
thanks,
-Will
|
| view message |
| Creating a multipage hopscotch tour |
| (1 response) |
Deanna |
2018-06-26 12:45 |
|
I am trying to create a multipage tour, using the tour builder.
I have successfully created callouts on our Home page however, once the tour moves to the 2nd page I cannot get the callouts to start.
How can this be fixed.
|
| view message |
| Notification Issues |
| (1 response) |
slatour |
2018-06-12 08:24 |
|
I am using LabKey to communicate via message boards. Currently we have noticed that we cannot trigger an email notification to project users unless a body of text is added. Sometimes colleagues use only the title to communicate an announcement. Is there a setting to allow for all new announcements/messages to trigger an email? Or is this a system design to only allow the notifications if a body of text is added?
Kind Regards,
Sara
|
| view message |
| Bug when clearing a dual-filtered column |
| (5 responses) |
Will Holtz |
2018-06-10 09:00 |
|
Hi,
Here is a reproduction of what looks like a bug to me:
- http://localhost:8080/labkey/query/home/executeQuery.view?schemaName=core&query.queryName=Users
- Click on email column header -> Filter...
- Create dual filter with "Contains" the string "@" and "Is Not Blank"
- Try to remove the "Is Not Blank" filter by click on the orange ''X' by the filter description in the grid header.
Result: Both filters are removed
Expected: Only Is Not Blank filter is removed and Contains @ filter is retained.
-Will
|
| view message |
| Changing display/header name for study's subject ID field |
| (1 response) |
olnerdybastid |
2018-06-08 16:03 |
|
I have a study that was initialized to display subject IDs as "Subject ID" in Manage -> Change Study Properties -> Subject Column Name. Now I've been asked to standardize the way all the identifiers are displayed across our study and change this display to "SubjectID" (remove the space). I've tried both changing the value in Subject Column Name to reflect this as well as individually setting the columnTitle value for all of my datasets in datasets_metadata.xml and re-importing dataset definitions, but all my datasets still display "Subject ID" in their header.
Oddly, if I change the Subject Column Name to something else with a space in it, like "my friends", it will display as "myfriends" without a space. But it won't subtract the space if I set the display name to "Subject ID"--inconveniently the one instance where I don't want it to preserve the space. I don't see any constraints on this field's display name in the docs here (https://www.labkey.org/Documentation/wiki-page.view?name=studyFields). Is there a way for me to change this field's header to display the way I want?
|
| view message |
| 500 Error when accessing the fileContentSummary.view for certain folders |
| (3 responses) |
Brian Connolly (Proteinms.net) |
2018-06-07 17:13 |
|
I have written a script which crawls the LabKey Server project list to determine the FileRoot for a given project and if any subfolders might be using a custom file or pipeline root. The script finds this information by accessing fileContentSummary.view for each container.
One our server, there are a number of folders where this view returns a HTTP response code of 500 with JSON output of
{
"exception" : "Malformed input or input contains unmappable characters: /path/to/files/on disk/",
"exceptionClass" : "java.nio.file.InvalidPathException",
"stackTrace" : [ "sun.nio.fs.UnixPath.encode(UnixPath.java:147)", "sun.nio.fs.UnixPath.<init>(UnixPath.java:71)", "sun.nio.fs.UnixFileSystem.getPath(UnixFileSystem.java:281)", "java.io.File.toPath(File.java:2234)", "org.labkey.filecontent.FileContentServiceImpl.getDefaultRootPath(FileContentServiceImpl.java:255)", "org.labkey.filecontent.FileContentServiceImpl.getFileRootPath(FileContentServiceImpl.java:216)", "org.labkey.filecontent.FileContentServiceImpl.getMappedDirectory(FileContentServiceImpl.java:666)", "org.labkey.filecontent.FileContentServiceImpl.getMappedAttachmentDirectory(FileContentServiceImpl.java:653)", "org.labkey.filecontent.FileContentServiceImpl.getNodes(FileContentServiceImpl.java:1181)", "org.labkey.filecontent.FileContentController$FileContentSummaryAction.getChildren(FileContentController.java:702)", "org.labkey.filecontent.FileContentController$FileTreeNodeAction.execute(FileContentController.java:794)", "org.labkey.filecontent.FileContentController$FileTreeNodeAction.execute(FileContentController.java:786)", "org.labkey.api.action.ApiAction.handlePost(ApiAction.java:180)", "org.labkey.api.action.ApiAction.handleGet(ApiAction.java:133)", "org.labkey.api.action.ApiAction.handleRequest(ApiAction.java:127)", "org.labkey.api.action.BaseViewAction.handleRequest(BaseViewAction.java:177)", "org.labkey.api.action.SpringActionController.handleRequest(SpringActionController.java:415)", "org.labkey.api.module.DefaultModule.dispatch(DefaultModule.java:1231)", "org.labkey.api.view.ViewServlet._service(ViewServlet.java:205)", "org.labkey.api.view.ViewServlet.service(ViewServlet.java:132)", "javax.servlet.http.HttpServlet.service(HttpServlet.java:742)", "org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:231)", "org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)", "org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:52)", "org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)", "org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)", "org.labkey.api.data.TransactionFilter.doFilter(TransactionFilter.java:38)", "org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)", "org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)", "org.labkey.api.module.ModuleLoader.doFilter(ModuleLoader.java:1138)", "org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)", "org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)", "org.labkey.api.security.AuthFilter.doFilter(AuthFilter.java:214)", "org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)", "org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)", "org.labkey.core.filters.SetCharacterEncodingFilter.doFilter(SetCharacterEncodingFilter.java:118)", "org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)", "org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)", "org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:198)", "org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96)", "org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:496)", "org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:140)", "org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:81)", "org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:650)", "org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:87)", "org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:342)", "org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:803)", "org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66)", "org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:790)", "org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1459)", "org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49)", "java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)", "java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)", "org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)", "java.lang.Thread.run(Thread.java:748)" ]
}
To access this page I am using a URL similar to https://panoramaweb.org/home/filecontent-fileContentSummary.view??node=CONTAINERID
Is this error occurring when the server is reading the file path from the database or is the server attempting to access the filesystem and the information returned from the filesystem is bad or encoded in some bad way.
Please note, we have had some filename encoding problems where the server was using UTF-8 encoding when storing the file/directory names in the database, but filesystem was using something different (such as ISO-8859-2). This is most like the cause, but I want to verify it is not something else.
Brian
|
| view message |
| Assay run imports are successful, but no data rows are visible |
| (4 responses) |
jmb |
2018-06-06 12:57 |
|
I have an assay defined with multiple batches/runs uploaded that were previously uploaded successfully and a trigger script to populate additional columns. Recently I tried to re-import one of my runs after making some edits to my trigger script. The re-import was successful in that no errors are thrown and the new run shows up in my Assay Runs webpart, but when I clicked on the newly created run name (or the View Results button) to view the assay results I didn't see any associated data rows.
To troubleshoot, I decided to delete my existing batches/runs/data and import them from scratch to see if this would resolve the issue. But I am seeing the same issue now when importing 'new' data: the run itself imports and is visible in the webpart, clicking on the run returns no rows associated with the new Run integer id. And if I remove the 'Run=[###]' filter while viewing assay results I still see an empty grid displaying 'No data to show'.
So far I've verified that this same behavior occurs even after I disable my trigger script. I've also verified that new records are being inserted into the underlying postgres tables (exp.experimentrun, exp.data, and assayresult.c5d91_nanodrop_qc_data_fields) after import, as shown in the query below:
Before importing a new run:
labkey=# SELECT rowid FROM exp.experimentrun;
rowid
-------
1
2
(2 rows)
labkey=# SELECT DISTINCT dataid FROM assayresult.c5d91_nanodrop_qc_data_fields;
dataid
--------
(0 rows)
The same two queries after import:
labkey=# SELECT rowid FROM exp.experimentrun;
rowid
-------
1
2
136
(3 rows)
labkey=# SELECT rowid,dataid FROM assayresult.c5d91_nanodrop_qc_data_fields;
3750 | 269
3751 | 269
3752 | 269
3753 | 269
3754 | 269
3755 | 269
3756 | 269
3757 | 269
3758 | 269
3759 | 269
3760 | 269
3761 | 269
3762 | 269
3763 | 269
3764 | 269
3765 | 269
3766 | 269
3767 | 269
3768 | 269
3769 | 269
3770 | 269
3771 | 269
3772 | 269
3773 | 269
3774 | 269
3775 | 269
3776 | 269
(39 rows)
Any ideas on how to fix this would be much appreciated. Thanks.
|
| view message |
| X! Tandem search error with trypsin/chymotrypsin |
| (1 response) |
t s loo |
2018-05-21 03:51 |
|
Good evening,
It seems the pipeline looks for [FKLMRWY]|{P} for trypsin/chymotrypsin digest but the GUI inputs as strict chymotrypsin in the XML:
<note label="protein, cleavage site" type="input">[RKWYF]|{P}</note>
I tried to correct the XML script to match and the GUI came up with an error: The enzyme '[RKWYFML]|{P}' was not found.
Is there a quick fix for this?
Best regards,
Trevor
Windows 7 Enterprise SP1 (64 bit)
Firefox Quantum 60.0.1 (64 bit)
Labkey v18.1-57017.17
Sorry there isn't an error code other than the following (trimmed out the list of accepted enzymes except the one in question).
21 May 2018 22:20:10,500 INFO : ERROR: Unsupported search enzyme.
21 May 2018 22:20:10,501 INFO : Use one of the following cleavage site specifications:
21 May 2018 22:20:10,508 INFO : trypsin/chymotrypsin - [FKLMRWY]|{P}
21 May 2018 22:20:10,504 INFO : Failed to complete task 'org.labkey.ms2.pipeline.tandem.XTandemSearchTask'
21 May 2018 22:20:10,510 ERROR: Failed running C:\Program Files (x86)\LabKey Server\bin\Tandem2XML, exit code 1
|
 JTy_TC_PK1-2h.log JTy_TC_PK1-2h.log |
| view message |
| The schema for the reagent module did not appear. Why? |
| (3 responses) |
Bika |
2018-05-20 06:54 |
|
Hi, After installing the reagent module, I found that the schema is not available in the labkey (see as Reagent-1). The reagent schema can be seen through pgAdmin(see as Reagent-2).I am in urgent need of reply.Thanks!
|
| Reagent-1.PNG Reagent-2.PNG |
| view message |
| Panorama QC Plot 'Create Guide Set' Grayed Out |
| (2 responses) |
lubwen |
2018-05-18 16:27 |
|
Hi All,
We installed LabKey server since we would like to use Dr. Michael MacCoss' AutoQC program to help QC our mass specs. We were able to upload data to the server using the AutoQC program.
However, we were not able to create guide set using our uploaded data. One key component of the QC process is the Pareto Analysis. And to perform Pareto Analysis one needs to be able to create a 'Guide Set'. On our QC Plot dashboard, however, the "Create Guide Set" is grayed out. I am attaching a screenshot of the grayed out button. When I moused over the grayed out button, it says "Enable/disable Create Guide Set mode". I suspect that I need to "enable Create Guide Set mode" somewhere. I looked around and could not figure out how to enable this "Create Guide Set Mode".
Any suggestion will be very much appreciated. Best regards,
|
| QC_Plot_Guide-Set-Gray-Out.jpg |
| view message |
| Non-responsive UI buttons on bottom of page |
| (5 responses) |
olnerdybastid |
2018-05-08 19:43 |
|
Posting here since I don't know if there's another more appropriate place for reporting a possible bug:
This may be a known issue already, but I have found that on very long forms in LabKey where the Submit or Cancel buttons are pushed to the very bottom of my browser window, these buttons are non-responsive (can't be clicked, no cursor change on mouse-over, etc.). I've seen this happen on multiple LabKey interfaces, but one reproducible example is navigating the Insert New Row page for a dataset where many fields are defined (30+ or so). I am using Safari 11.0.3 and Firefox 59.0.2, and both seem to exhibit this behavior. Fortunately it's not a problem on forms where there are a pair of Submit buttons on both the bottom and top of the page, since the top buttons seems to work consistently as expected.
|
| view message |
| Required Date column for demographic dataset in a study without timepoints |
| (3 responses) |
olnerdybastid |
2018-04-30 20:09 |
|
Lately I've been curious as to why there is a requirement for a date column in demographic datasets in LabKey, and whether there is any way I might bypass this requirement. A number of the datasets we collect are demographic in nature, so having to arbitrarily add a date is not ideal. Is there a safe workaround for this, either by modifying the table in Postgres directly (which I'm guessing voids my warranty and is a very bad idea) or by making edits to some underlying XML for our demographic datasets?
Relatedly, in non-demographic datasets we collect where records ARE tied to a specific date, is there a way for me to redefine one of my dataset's existing datetime fields to serve as part of the table's multi-column key (instead of the generic 'Date' column that comes standard with every Dataset) ? For instance, let's say I have a dataset where each row is uniquely identified by both a SubjectID and a datetime field we call 'ChartReviewDate'. Rather than have to populate the 'Date' column with the value from 'ChartReviewDate', is there a way for me to rename 'Date' to something more informative/modify the header so a more descriptive name appears in the grid view?
|
| view message |
| Weird Editing Permissions error |
| (1 response) |
Nat |
2018-04-24 12:25 |
|
I had granted editing permissions to a colleague (mwfoster@duke.edu (mwfoster)) to work on our Duke University Course page: https://skyline.ms/project/home/software/Skyline/events/2018%20Duke%20Course/begin.view?
When making an edit and trying to save he gets a very odd error that says:
“error saving wiki” in the basic editor or “rel attribute
must be set to noopener noreferrer with target=”_blank”. Error on element <a>.” in the advanced
editor.
The only way we could work around this was removing all the "target=”_blank”" tags from the page ...
I got the same error when I impersonated him but did not when I tried to edit as myself.
Attached is the thread we had about this ...
Nat
|
 Re FW New account on Skyline Website.txt Re FW New account on Skyline Website.txt |
| view message |
| Weird Labkey errors |
| (2 responses) |
Nat |
2018-04-24 12:10 |
|
Hi,
LabKey is giving us weird graphical errors this morning. Even as I write this post, there is a blank area above that looks like some sort of scripting error. On our Skyline server the blank area is over the Save button so there is no way to make changes -- just have to refresh the page. Only happens in Chrome. Works fine in firefox.
see attached graphic.
|
| Error1.JPG |
| view message |
| insert data to server |
| (1 response) |
rqi |
2018-04-20 07:35 |
|
from labkey.query import insert_rows
I used insert_rows(server_context, schema, table, row) to insert my data.
It worked but usually it took 10 minutes to upload a small size data set like 50 kb. Is there any log file I can check what is happening in the 10 mins?
If I tried to upload 10 different data sets to the same table, it worked for the first data set but failed for the 2nd one. Exception said: 500: SqlExecutor.execute(); SQL []; An I/O error occurred while sending to the backend.; nested exception is org.postgresql.util.PSQLException: An I/O error occurred while sending to the backend.
What might be the reason? Many people said it might be connection issue. If yes, how can I try to solve the problem?
Thanks very much
|
| view message |
| Audit record of downloads from the file system |
| (1 response) |
mjavadi |
2018-04-03 08:38 |
|
Hello,
I was looking at the audit tables on postgres and found that audit.filesystemauditdomain table contains audit logs of files being uploaded and deleted from the file system, however no records of file downloads. Is there another table that keeps an audit trail of downloads made from the file system?
Thank you,
Mojib
|
| view message |
| How do we connect data on Labkey to Tableau Server? |
| (1 response) |
Chidi |
2018-04-03 08:32 |
|
We have some data on Labkey that we would like access from Tableau Server. How can we go about doing that? Thank you.
|
| view message |
| How do I hide a column in a dataset from another user? |
| (1 response) |
Chidi |
2018-04-03 08:29 |
|
As a site and folder admin, what is the best way for me to hide a column in a dataset from a user (who is an editor) in a given folder? I have a sensitive data information I wouldn't like to share with everyone. I have the community edition. Thanks.
|
| view message |
| do I need to be system administrator to insert data? |
| (1 response) |
rqi |
2018-03-26 12:44 |
|
I have the right to modify data of the project based on the labkey user setting. I am trying to insert data by ssh to the server. If I am system administrator, I can run the code to insert data. If I am not, I always got exception like: RequestAuthorizationError: '401: User does not have permission to perform this operation'. Do I need to be system administrator? Or there might be other reason? Thanks. Help needed!
|
| view message |
| verify server_context is configured correctly |
| (1 response) |
rqi |
2018-03-26 12:33 |
|
I tried to install Python API for LabKey Server on my windows machine to remotely manage data on linux machine.
What I did:
1 pip install labkey
2 add labkey to my project;
3 Set Up a netrc File on the home directory
machine labkey.*****.org
login &&@*****.org
password *****
My code:
server_context = create_server_context(server, project, context_path, use_ssl=False)
server=labkey.*****.org:80
project="apple\ pear" (Note: on my server, the project name has a space so I used back slash)
context_path=labkey
But I always got error said: server_context = create_server_context(server, project, context_path, use_ssl=False)
Please help! Thanks
|
| view message |
| Latest LabKey has a NullPointerException on docker |
| (1 response) |
scchess |
2018-03-23 00:00 |
|
https://github.com/LabKey/samples/tree/master/docker/labkey-standalone is a docker image for LabKey.
I have downloaded the latest LabKey, Java and Tomcat for the Labkey docker. "java' is accessible in the docker (otherwise TomCat would not have even started). I started the docker like in the first attachment.
The server started. But LabKey had a NullPointerException (see attachment S2).
Why did LabKey passed a NULL to a function that expected a non-null object?
I'm running the latest Java 10 on the docker. Is Java 10 too new for LabKey? Please note the original docker used Java 1.7. Looking at the source code
https://hedgehog.fhcrc.org/tor/stedi/branches/release18.1/server/api/src/org/labkey/api/module/ModuleLoader.java
It looks like "JavaVersion.JAVA_1_8" is a null object?
|
| S1.png S2.png |
| view message |
| Project Number Display Format reverts to previous setting |
| (1 response) |
dennisw |
2018-03-22 07:18 |
|
Hi,
We are using LabKey 17.2. When setting a number display format via admin > folder > project settings and then entering a format in the 'Default Display Format for Numbers', it seems that once I've entered a value I can change that value but when I try to clear out that input field entirely and then Save it reverts back to the previous format I had entered.
I had, incorrectly, entered %.12f thinking I should enter a string formatting format, but then realized that what I really wanted was just 0 (so as not to have long integers displayed as Scientific Notation). The 0 works fine, but when I cleared the 0 and clicked save, it reverts back to showing (and applying) the %.12f format.
|
| view message |
| New UI and grid paging |
| (1 response) |
Will Holtz |
2018-03-15 12:11 |
|
With the updated UI, I found it hard to locate the grid paging menu. It was unclear to me that the range display ("1-100 of 1534") was a drop-down menu. The other drop-down menu items along the top of the grid have a down arrow to the right of them. For consistency, I would suggest adding a down arrow next to the range display too.
Additionally, has the paging 'show all' functionality been removed? I'm not seeing that option anymore and I know it gets used on my site.
thanks,
-Will
|
| view message |
| Merging/Changing Participant IDs in Bulk |
| (5 responses) |
slatour |
2018-03-07 06:51 |
|
Hi,
I have created a demographics data set in which one column corresponds to a Lab ID and the other column refers to an alias ID. The data has been imported to the study already. After multiple researchers have added data to the study we realized the ID columns require to be switched. I have previously used the Merge Participant IDs function within the Manage Study -> Manage Aliases/Alternate Participant IDs section on LabKey. My issue is that this only allows for one data overwrite at a time. considering I have 500+ Ids to change I was wondering if there is an alternate solution to doing this manually one by one?
Any help would be greatly appreciated!
Cheers,
Sara
|
| view message |
| Luminex module |
| (2 responses) |
SISTM |
2018-03-07 04:52 |
|
Hi,
I'm trying the luminex tutorial on a DOCKER instance.
I started this tutorial : https://www.labkey.org/Documentation/wiki-page.view?name=importLuminexRunData.
Trying the tutorial with 02-14A22-IgA-Biotin.xls worked like a charm, but I got issues trying to import another file after the first import.
I have no error during new import (ex : 04-17A32-IgA-Biotin.xls), but in the Luminex Assay 100 Runs table, if I click 04-17A32-IgA-Biotin.xls to see the imported data for the run, the data grid is empty.
To summarize, first import is OK, but the data grid is empty for the following imports (without any error message).
LABKEY Version : 17.3
Release Date : 2018-01-30
Build Number : 56184.53
Please help, thanks.
|
| view message |
| ClinCapture & Laboratory equipment integration for study |
| (1 response) |
scott |
2018-03-03 08:09 |
|
Hello,
In the midst of integrating ClinCapture with Labkey for an upcoming clinical study. Currently we are performing test where we export normalized CRF data from ClinCapture (either in xls or other format) and then import into Labkey. We have split demographic and medical history information into two separate Labkey datasets (clinical demographic fields --> labkey demographic dataset due to the one-to-one primary key limitations of subjectID), however we are not sure about the proper way to handle the normalized medical history information (one-to-many, e.g. subjectID may have multiple entries). Would this be best handled as a clinical dataset or an assay dataset?
Then, then next issue - which is related - is that Clincapture exports are cumulative (all completed CRFs are included for each export), which makes the Labkey importing process tricky. Have others dealt with this before, how is the best way to manage this information.
Finally, we want to consolidate multiple analytical results (Flow, LCMS, ELISA, etc..) for each patient back in Labkey - presumably these are assay datasets, but I am worried that when we import the next batch of patients, we may wipe out the earlier results.
The ultimate goal is to enable a robust data structure for subsequent informatics (via R) across all of these dimensions for analysis.
Hopefully this seeming common scenario has been figured out by the Labkey community and someone can guide me through the study setup / assay dataset configuration process properly.
Thanks!
|
| view message |
| Data Finder like in ITN TrialShare |
| (2 responses) |
christine rousseau |
2018-02-21 01:37 |
|
|
|
| view message |
| Unable to view deuterated heavy internal standard in LC chromatogram |
| (3 responses) |
wongk38 |
2018-02-14 16:53 |
|
Hi,
The latest Skyline software 4.1 doesn't allow for the viewing of deuterated heavy internal standard when we open up previous Skyline document (v 3.7) containing results.
I've attached some photos to show the differences between the 2 software. Ideally, it would be nice if the updated Skyline version would be able to view the previous results from the older Skyline version.
What would be the best path forward to address this issue?
Many thanks!
Kent
|
| Skyline daily.png |
| view message |
| Separating Database from Webserver? |
| (1 response) |
olnerdybastid |
2018-02-08 16:59 |
|
Background: We are in the planning stages of building a platform for managing clinical and genetic data that will contain sensitive PHI and are considering LabKey for our project.
Having worked through the LabKey tutorials, I’m familiar with the safeguards in place for restricting access to PHI. However, for security reasons we are not sure that we want PHI to reside on a server that is exposed to the internet. If I’ve understood the docs correctly, storing our PHI in an external database would present some limitations in how we’re able to make queries, since Joins and Lookups across internal and external data sources are not supported and defining the core LabKey Server schemas as external schemas seems to be strongly discouraged
In light of all this, I’m wondering what options we’d have that would allow us to make use of the front-end capabilities and hopefully the schema designs already implemented in LabKey while keeping our database separate from the web server/how other developers have approached this?
|
| view message |
| Cutom data grid read access for guest |
| (1 response) |
John M |
2018-01-31 01:48 |
|
Hi,
I have made a customer data grid based on a dataset and saved this under a new name. I would like to give a guest role user, read access to only this new saved custom grid view.
Is this possible?
From testing this out the user is only able to read the custom grid once I have given them rights to the whole dataset itself.
This feature would be useful to share subsets of data with other organisations, without showing all of the data.
Thank you for any advice.
John
|
| view message |
| Beginners Question on Specimen Import |
| (1 response) |
meyer |
2018-01-28 05:52 |
|
Hi,
thanks for any assistance on the following situation:
I've set up a study, initialized an 'Advanced Specimen Repository' with data editable and requensts enabled, intending to populate the repository via upload/import of external data (just Excel file, no external software, not a LabKey archive, but columns as exported from demo repository or from own repository with two manually incerted specimen).
Whenever uploading and then importing a specimen file the system indicates a successful import process, at least it says 'COMPLETED'. Looking into the log file reveals, that no Patient ID was found:
----------------------------------------------------
28 Jan 2018 14:23:22,690 INFO : Starting to run task 'org.labkey.study.pipeline.StandaloneSpecimenTask' at location 'webserver'
28 Jan 2018 14:23:22,706 INFO : Unzipping specimen archive C:\Program Files (x86)\LabKey Server\files\FCCM\@files\SpecimenRepository\SpecimenFake_2018-01-28_12-15-56.specimens
28 Jan 2018 14:23:22,721 INFO : Expanding specimens.tsv
28 Jan 2018 14:23:22,753 INFO : Archive unzipped to C:\Program Files (x86)\LabKey Server\files\FCCM\@files\SpecimenRepository\180128142322721
28 Jan 2018 14:23:22,768 INFO : Starting specimen import...
28 Jan 2018 14:23:22,893 INFO : Creating temp table to hold archive data...
28 Jan 2018 14:23:23,112 INFO : Created temporary table temp.SpecimenUpload$445bcbace64f1035ac18e39b7fd70b50
28 Jan 2018 14:23:23,112 INFO : Populating specimen temp table...
28 Jan 2018 14:23:23,143 INFO : temp.SpecimenUpload$445bcbace64f1035ac18e39b7fd70b50: No rows to replace
28 Jan 2018 14:23:23,159 INFO : Found no specimen columns to import. Temp table will not be loaded.
28 Jan 2018 14:23:23,253 INFO : Created indexes on table temp.SpecimenUpload$445bcbace64f1035ac18e39b7fd70b50
28 Jan 2018 14:23:23,253 INFO : Specimens: 0 rows found in input
....
----------------------------------------------------
Patient ID is available in each of the different xls-tables tested for import. Nothing shows up in the specimen list anyway.
What is the problem I'm facing? What is it I didn't extrct from the documentation?
Thanks for any hint!
Claudius
|
| view message |
| Use of cookie still working in labkey 17.x for non-api page ? |
| (2 responses) |
toan nguyen |
2018-01-24 12:59 |
|
|
|
| view message |
| ETL - Data Transform |
| (1 response) |
marcia hon |
2018-01-19 08:00 |
|
Hello,
I cannot seem to be able to connect to: etl xmlns=" http://labkey.org/etl/xml" .
This is preventing me from seeing the ETL jobs.
Please let me know how to correct this.
Thanks,
Marcia
|
| view message |
| Sequential Keys |
| (1 response) |
marcia hon |
2018-01-18 11:54 |
|
Hello,
We would like for there to be columns that autoincrement given a seed value.
For example, in table A, we would like the key to start at 10000. Each time something is uploaded the key changes by adding 1.
And another table B, starting at 20000. Each time uploaded, key changes by adding 1.
Please let us know how this is possible.
Thanks,
Marcia
|
| view message |
| very slow import of ProteinProphet data |
| (14 responses) |
tvaisar |
2018-01-10 20:44 |
|
Labkey support team,
We started to notice that upload of ProteinProphet results has become rather slow. While before it would take few minutes now it takes nearly an hour for a data file. Looking back through our logs it appears the slowdown coincides with upgrade to 17.2 version and specifically since when we updated 17.2 community release to build 54372 we got from Josh Eckels to allow us to upload Panorama chromatogram libraries.
I would appreciate any suggestion of where to start looking for leads to troubleshoot this problem.
We run it on CentOS Linux box with PostgreSQL 9.4..4.
Thanks a lot,
Tomas Vaisar
|
| view message |
| Detection and integration of large molecules |
| (1 response) |
fuyanli |
2018-01-08 14:02 |
|
Hi,
I am now working on large molecules such as archaeal GDGTs (m/z: 1302, 1300, 1298, 1296, 1292). I used QExactive with ESI to detect such archaeal membrane lipids which were ionized by Na, NH4 and H. I want to try to use Skyline to integrate these compounds and calculate the peak area. But I am not sure if the peak algorithm used in Skyline is suitable for these large molecules. Is there anyway to calculate the signal to noise ratio (S/N) in Skyline? What method is used in Skyline for S/N?
Thanks,
Fuyan
|
| view message |
| Wikis and developer permissions |
| (1 response) |
eva pujadas |
2018-01-08 08:25 |
|
Dear LabKey support team,
We would like to give our project users the possibility to develop LabKey wiki pages with advanced functionality, that is, allowing them to use certain HTML tags like <form> and <input>, even to use JavaScript. That requires to give them Developer permissions, which would allow them also to write R scripts and reports. Since we are using a shared server, there would be the risk of accessing data at the file level for which they do not have permissions.
Is there a way of giving a project administrator the possibility to use certain HTML tags without having to grant them full server developer permissions?
Thanks and best,
Eva Pujadas
|
| view message |
| Failing to upgrade LabKey |
| (1 response) |
jmikk |
2018-01-08 07:45 |
|
Hello there,
I recently attempted to upgrade LabKey from 17.1 to 17.3. During the upgrade process, everything was going smoothly until LabKey tried to update the SqlScriptManager module. I get lots of PSQLExceptions in labkey.log (attached). After wiping the database, restoring from a 17.1 backup and trying to update again, I still ran into the same issues and was forced to abort the upgrade. We are now running smoothly, still on 17.1.
What are our options for upgrading LabKey in the future? It seems like our future upgrades are bound to fail. In the past, we had upgraded to 17.2 but downgraded back down to 17.1 after finding out that some of our DISCVR modules were not compatible yet. I'm wondering if this downgrade has caused some issues.
Thanks!
|
| labkey-error-log.log |
| view message |
| Labkey functions |
| (3 responses) |
srivastava aman2 |
2018-01-08 01:32 |
|
Hi All,
I want to partition duplicate data in labkey. I am trying Row_Number & Rank().
For ex: RANK() OVER (PARTITION BY field1ORDER BY field2).
But, it is non supported function of labkey. Please suggest any alternatives for this?
|
| view message |
| Tableau Server Connectivity Issue with SparkSQL Connector |
| (1 response) |
Elena Kretova |
2017-12-18 00:23 |
|
I have a Tableau Report which I have created on Tableau Desktop using Spark SQL Connector. I am using Databricks for Spark Execution Engine. The same report when I am trying to publish and view on Tableau Server https://tekslate.com/tableau-server-training , it is giving Driver/Access Issue (screenshot attached). I have admin access to Server though and server in running as well.
Do I need to install additional drivers on Server to get the same connected ? Apologies for my limited knowledge of Tableau Server.
|
| view message |
| Barcode / QR code reader |
| (1 response) |
eva pujadas |
2017-12-04 00:38 |
|
Dear Labkey supporters,
We would like to integrate a barcode and a QR code scanners in two of our LabKey projects. Do you know about any external module, JavaScript possibility to embed in a LabKey wiki page or other kind of solution?
Thanks a lot.
Best regards,
Eva
|
| view message |
| job stuck waiting status |
| (5 responses) |
toan nguyen |
2017-12-01 14:33 |
|
Hi,
a user submit a job but it is stuck in waiting status in the activemq log after it finish the first FAASTA check.
01 Dec 2017 11:40:26,278 INFO : X! Tandem search for all
01 Dec 2017 11:40:26,281 INFO : =======================================
01 Dec 2017 11:40:26,283 INFO : abac.mzXML
01 Dec 2017 11:40:26,285 INFO : casfdsa.mzXML
01 Dec 2017 11:40:26,287 INFO : cafdsa.mzXML
01 Dec 2017 11:40:26,288 INFO :dsafsa.mzXML
01 Dec 2017 11:40:26,845 INFO : Starting to run task 'org.labkey.ms2.pipeline.FastaCheckTask' at location 'webserver-fasta-check'
01 Dec 2017 11:40:26,854 INFO : Check FASTA validity
01 Dec 2017 11:40:26,856 INFO : =======================================
01 Dec 2017 11:40:26,912 INFO : Checking sequence file validity of xxxxxxxxxxxx.fasta
01 Dec 2017 11:40:29,534 INFO :
01 Dec 2017 11:40:29,537 INFO : Successfully completed task 'org.labkey.ms2.pipeline.FastaCheckTask'
The labkey.log show
INFO Job 2017-12-01 11:40:29,539 JobRunnerFastaCheckUMO.1 : Successfully completed task 'org.labkey.ms2.pipeline.FastaCheckTask' for job '(NOT SUBMITTED) Phospho (Trypsin_phosphorylation_no_fractions)' with log file xxxxxx.xxxxxx/all.log
The activemq job.queue shows job in waiting status. Can someone help ? I don't see any thing in the log that what is it waiting for ? submitted ?
<__submitted>false</__submitted>
Thanks
Toan.
ACTIVEMQ_HOME: /usr/local/apache-activemq-5.1.0
ACTIVEMQ_BASE: /usr/local/apache-activemq-5.1.0
JMS_CUSTOM_FIELD:LABKEY_TASKSTATUS = WAITING
JMS_CUSTOM_FIELD:MULE_SESSION = SUQ9N2FkNjJiYjQtZDZjZi0xMWU3LWFlM2UtOWZhNmIyZWQyMGRkO0lEPTdhZDYyYmI0LWQ2Y2YtMTFlNy1hZTNlLTlmYTZiMmVkMjBkZA==
JMS_CUSTOM_FIELD:MULE_ORIGINATING_ENDPOINT = endpoint.jms.job.queue
JMS_CUSTOM_FIELD:LABKEY_JOBID = b56c9169-b85d-1035-a396-e7f1a88b84ba
JMS_BODY_FIELD:JMSText = <org.labkey.ms2.pipeline.tandem.XTandemPipelineJob>
<__dirSequenceRoot>file:xxxxxxxxxxxxxxxxxxxxxxxxxxxxx/</__dirSequenceRoot>
<__fractions>false</__fractions>
<__protocolName>Trypsin_phosphorylation_no_fractions</__protocolName>
<__joinedBaseName>all</__joinedBaseName>
<__baseName>xxxxxxxxxxxx</__baseName>
<__dirData>file:/xxxxxxxxxxxxxx</__dirData>
<__dirAnalysis>file:/sxxxxxxxxxxxxxxxxxxxxxxxxxxxx/</__dirAnalysis>
<__fileParameters>file:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx/tandem.xml</__fileParameters>
<__filesInput class="java.util.Collections$SingletonList">
<element class="file">file:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.mzXML</element>
</__filesInput>
<__inputTypes>
<org.labkey.api.util.massSpecDataFileType>
<__suffixes>
<string>.msprefix.mzXML</string>
<string>.mzXML</string>
</__suffixes>
<__antiTypes/>
<__defaultSuffix>.mzXML</__defaultSuffix>
<__contentTypes class="java.util.Collections$EmptyList"/>
<__dir>false</__dir>
<__preferGZ>false</__preferGZ>
<__supportGZ>true</__supportGZ>
<__caseSensitiveOnCaseSensitiveFileSystems>true</__caseSensitiveOnCaseSensitiveFileSystems>
<__extensionsMutuallyExclusive>true</__extensionsMutuallyExclusive>
</org.labkey.api.util.massSpecDataFileType>
</__inputTypes>
<__splittable>true</__splittable>
<__parametersDefaults>
<entry>
.......
<string>pipeline, database</string>
<string>ipi_human_plus.fasta</string>
<__info>
<__containerId>b1448d16-ee1c-1033-bfa5-0434ad51e74d</__containerId>
<__urlString>xxxxxxxxxxxxxxxxxxxx/searchXTandem.view?</__urlString>
<__userEmail>xxxxxx</__userEmail>
<__userId>1064</__userId>
</__info>
<__jobGUID>b56c9169-b85d-1035-a396-e7f1a88b84ba</__jobGUID>
<__parentGUID>b56c9110-b85d-1035-a396-e7f1a88b84ba</__parentGUID>
<__activeTaskId>org.labkey.ms2.pipeline.tandem.XTandemSearchTask</__activeTaskId>
<__activeTaskStatus class="org.labkey.api.pipeline.PipelineJob$TaskStatus">waiting</__activeTaskStatus>
<__activeTaskRetries>0</__activeTaskRetries>
<__pipeRoot class="org.labkey.pipeline.api.PipeRootImpl">
<__containerId>4fb97543-cf7a-1029-9fe6-f528764d84fc</__containerId>
<__uris>
<java.net.URI>file:xxxxxxxxxx</java.net.URI>
<java.net.URI>file:xxxxxxxxxxxx</java.net.URI>
</__uris>
<__entityId>4fb97544-cf7a-1029-9fe6-f528764d84fc</__entityId>
<__searchable>false</__searchable>
<__isDefaultRoot>false</__isDefaultRoot>
</__pipeRoot>
<__logFile>file:xxxxxxx.log</__logFile>
<__interrupted>false</__interrupted>
<__submitted>false</__submitted>
<__errors>0</__errors>
<__actionSet>
|
| view message |
| error after restart labkey/tomcat |
| (7 responses) |
toan nguyen |
2017-11-29 12:34 |
|
Hi,
Initially I have "transport is not running" which seems to point to activemq
I found out that activemq is not running so I started it. However; it still does not work.
So I restart labkey/tomcat however; tomcat seem taking forever to load and labkey seem to report the error below.
Would you please point me to the right direction to fix this ?
I am running labkey 15 on ubuntu 12.10.
Thanks
Toan.
INFO MuleManager 2017-11-29 12:05:57,495 Module Starter : Connectors have been started successfully
INFO MuleManager 2017-11-29 12:05:57,495 Module Starter : Starting agents ...
INFO MuleManager 2017-11-29 12:05:57,495 Module Starter : Agents Successf ully Started
ERROR eRetryConnectionStrategy 2017-11-29 12:06:12,307 UMOManager.4 : Failed to connect/reconnect: ActiveMqJmsConnector{this=3c46d6e5, started=false, initialised=true, name='jmsConnectorCloud', disposed=false, numberOfConcurrentTransactedReceivers=4, createMultipleTransactedReceivers=true, connected=true, supportedProtocols=[jms], serviceOverrides=null}. Root Exception was: Failed to start Jms Connection. Type: class org.mule.umo.lifecycle.LifecycleException
org.mule.umo.lifecycle.LifecycleException: Failed to start Jms Connection
at org.mule.providers.jms.JmsConnector.doStart(JmsConnector.java:504)
at org.mule.providers.AbstractConnector.startConnector(AbstractConnector.java:367)
at org.mule.providers.AbstractConnector.connect(AbstractConnector.java:1186)
at org.mule.providers.SimpleRetryConnectionStrategy.doConnect(SimpleRetryConnectionStrategy.java:76)
at org.mule.providers.AbstractConnectionStrategy$1.run(AbstractConnectionStrategy.java:57)
at org.mule.impl.work.WorkerContext.run(WorkerContext.java:310)
at edu.emory.mathcs.backport.java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1061)
at edu.emory.mathcs.backport.java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:575)
at java.lang.Thread.run(Thread.java:745)
|
| view message |
| Max Column Number |
| (1 response) |
marcia hon |
2017-11-27 10:58 |
|
Hello,
I wish to upload a dataset. It has thousands of columns.
Please let me know what size and dimensions is possible to upload. Also, how could this be uploaded.
Thanks
Marcia
|
| view message |
| Assays |
| (1 response) |
marcia hon |
2017-11-27 10:24 |
|
How can I edit rows/columns of an assay? How can I add rows to assays?
|
| view message |
| Demographics Dataset |
| (1 response) |
marcia hon |
2017-11-27 10:14 |
|
Hello,
I have two questions.
1. Does the Demographics dataset require a "Visit Id" column?
2. How do I insert a row into Demographics? I don't know what to put for "Date". It states: "Could not convert value: 1"
Thanks
Marcia
|
| view message |
| Electronic Health Records |
| (1 response) |
marcia hon |
2017-11-27 07:38 |
|
Hello,
How do you activate this feature? I tried creating a new project/study, but I don't know how to create an "Electronic Health Record".
Thanks,
Marcia
|
| view message |
| Study and Studydataset tables are empty |
| (3 responses) |
mjavadi |
2017-11-24 16:49 |
|
Hello,
I'm trying to load tables from postgres and whenever I try to load any of the 'studydataset' tables or any 'study' tables (i.e. 'participant', 'participantvisit', etc.) they are empty, in fact I get an error that data table does not contain any columns. However I can see these tables when I log-in under the study datasets.
Some of the 'studydataset' tables are assays which are then copied to study. The datatables that are copied to study from an assay do have the tables available under 'assayresult' tables. Other are datasets created directly in the study. Irrespective of the source, the 'studydataset' tables are empty.
Any assistance or insight you may have on how to resolve this issue would be much appreciated.
Thanks,
Mojib
|
| view message |
| Proteomics Error |
| (1 response) |
marcia hon |
2017-11-22 06:19 |
|
Hello,
I get an error: "Failed to locate tandem. Use the site pipeline tools settings to specify where it can be found. (Currently '/usr/local/labkey/bin')"
I believe it is because Tandem may not be installed.
Please let me know what caused this error, and what the solution is.
Thanks,
Marcia
|
| proteomics_tandem.png |
| view message |
| Proteomics Erro |
| (1 response) |
marcia hon |
2017-11-22 06:05 |
|
Hello,
I'm trying to follow the Proteomics tutorial. I am stuck on step one.
It appears that I cannot use my local drive to create a pipeline. However, in the instructions, it states that it is possible.
Please see attached.
I look forward to your feedback.
Thanks,
Marcia
|
| proteomics_pipeline.png |
| view message |
| why is TPP in such a abysmal state? |
| (1 response) |
pe243 |
2017-11-21 05:20 |
|
hi eveyone,
Maybe most popular among science/business distibution - Centos/Scientific Linux - and TPP ver. 4.8, 5.0, 5.1 they all fail to compile, only 4.7 managed to compile successfully. I've tried different compilers/toolsets and all versions above 4.7 do not compile.
Do you guys use any newer TPP version than what Labkey's docs suggest?
If yes, do these new versions compile for you?
My thoughts...
I'm no programmer but I thought before, TPP developers might live on a different planet, planet Windows but, I did not suppose that planet is in a far far away galaxy!
How could you release anything(not to mention carry on developing this way) without testing and proofing your software? Only, if you do not give a toss?
|
| view message |
| Specimen "Not Yet Submitted" |
| (1 response) |
marcia hon |
2017-11-17 12:32 |
|
Hello,
I have "Not Yet Submitted" as the default state with Final State = false and Lock Specimens = true.
When I click "edit" for any specimen, I am allowed to edit it. I thought this was not possible because it is by default in "Not Yet Submitted".
Please let me know where I am wrong. If there is some place to define this default behavior, please let me know.
Thanks,
Marcia
|
| view message |
| Specimen Requests |
| (1 response) |
marcia hon |
2017-11-17 12:13 |
|
Hello,
Under "Specimen Overview" > "Specimen Requests",
Per request, I only see "Details" button.
There is supposed to be three buttons, but I only see one.
Please let me know what I should change.
Thanks,
Marcia
|
| view message |
| Sequences and Keys |
| (1 response) |
marcia hon |
2017-11-16 11:49 |
|
Hello,
Does Labkey have the ability to generate keys sequentially?
We have demographics we would like to upload and to have the ID created automatically.
Thanks,
Marcia
|
| view message |
| Filename for Annotations |
| (1 response) |
marcia hon |
2017-11-10 08:37 |
|
On the screen: "Site Administration" > "Protein Database Admin" > "Load Protein Annotations",
I get the error:
"Can't open file '/C:\Users\username\Desktop\uniprot_sprot.xml.gz"
I enter for Full file path: C:\Users\username\Desktop\uniprot_sprot_xml.gz
and I click "Load Annotations".
I am using a windows machine.
I look forward to your help.
Thanks,
Marcia
|
| view message |
| GO Annotation Manual Load Error |
| (3 responses) |
marcia hon |
2017-11-09 11:19 |
|
|
|
| view message |
| Specimen |
| (3 responses) |
marcia hon |
2017-11-09 07:34 |
|
Hello,
For Specimen Overview > Specimen Requests, I can only see "Details". I am missing "Submit" and "Cancel".
Please let me know how to correct this.
Thanks,
Marcia
|
| view message |
| Deleting Specimens |
| (3 responses) |
marcia hon |
2017-11-09 07:05 |
|
Hello,
I cannot delete specimens and get the following error: "Specimen may not be deleted because it has been used in a request."
Please let me know how to fix this.
Thanks,
Marcia
|
| view message |
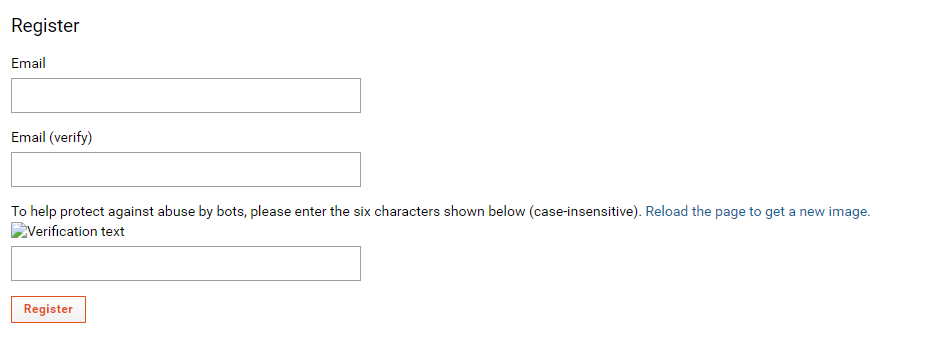 kaptcha.PNG
kaptcha.PNG parent-child-relation.png
parent-child-relation.png labkey-registration.png
labkey-registration.png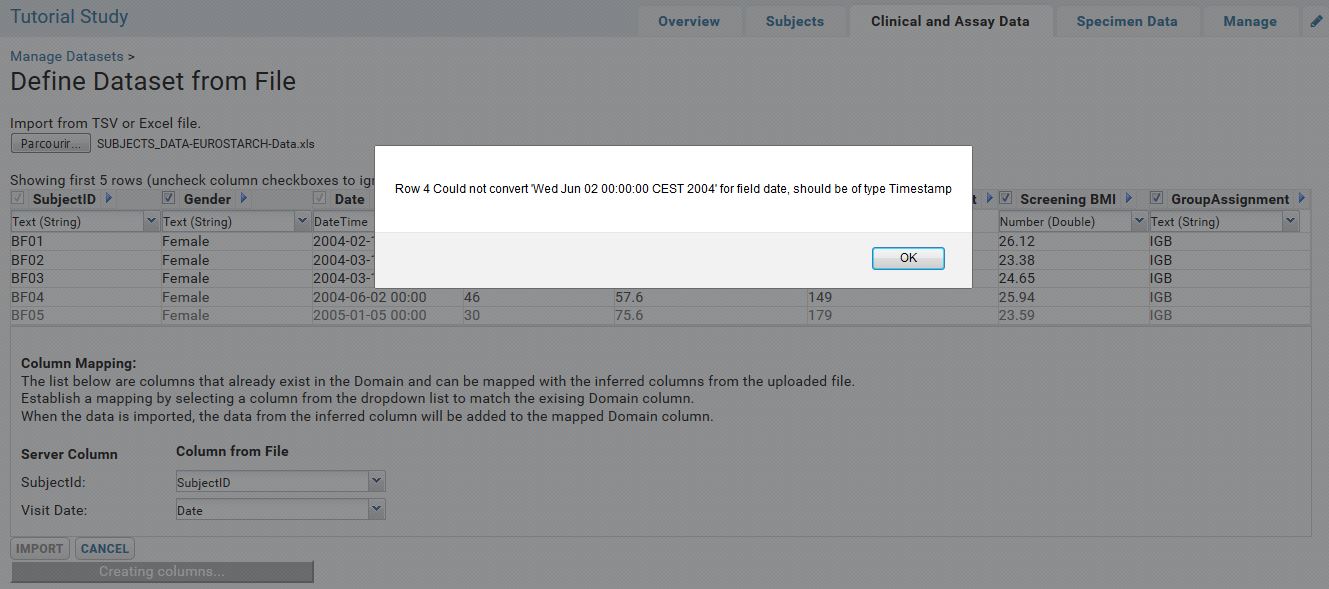 LabkeyErrorImport.JPG
LabkeyErrorImport.JPG image001.jpg
image001.jpg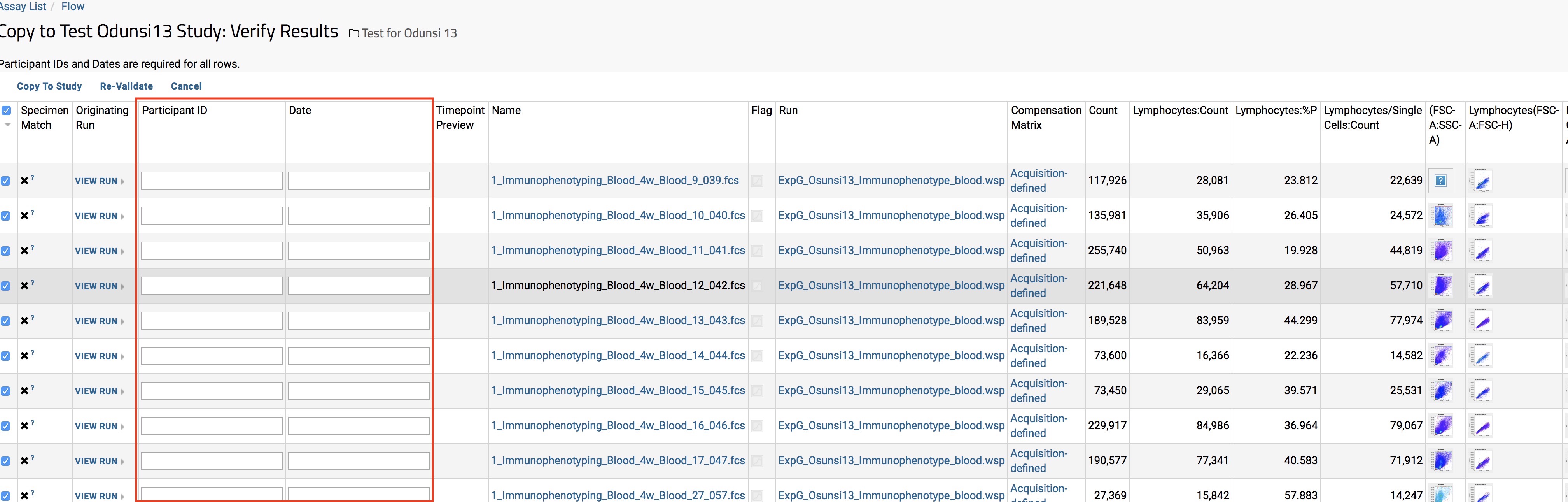 image002.jpg
image002.jpg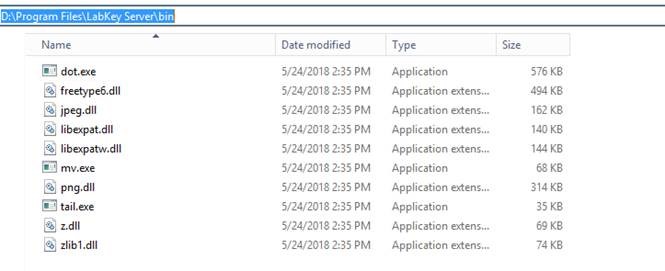 server_folder.jpg
server_folder.jpg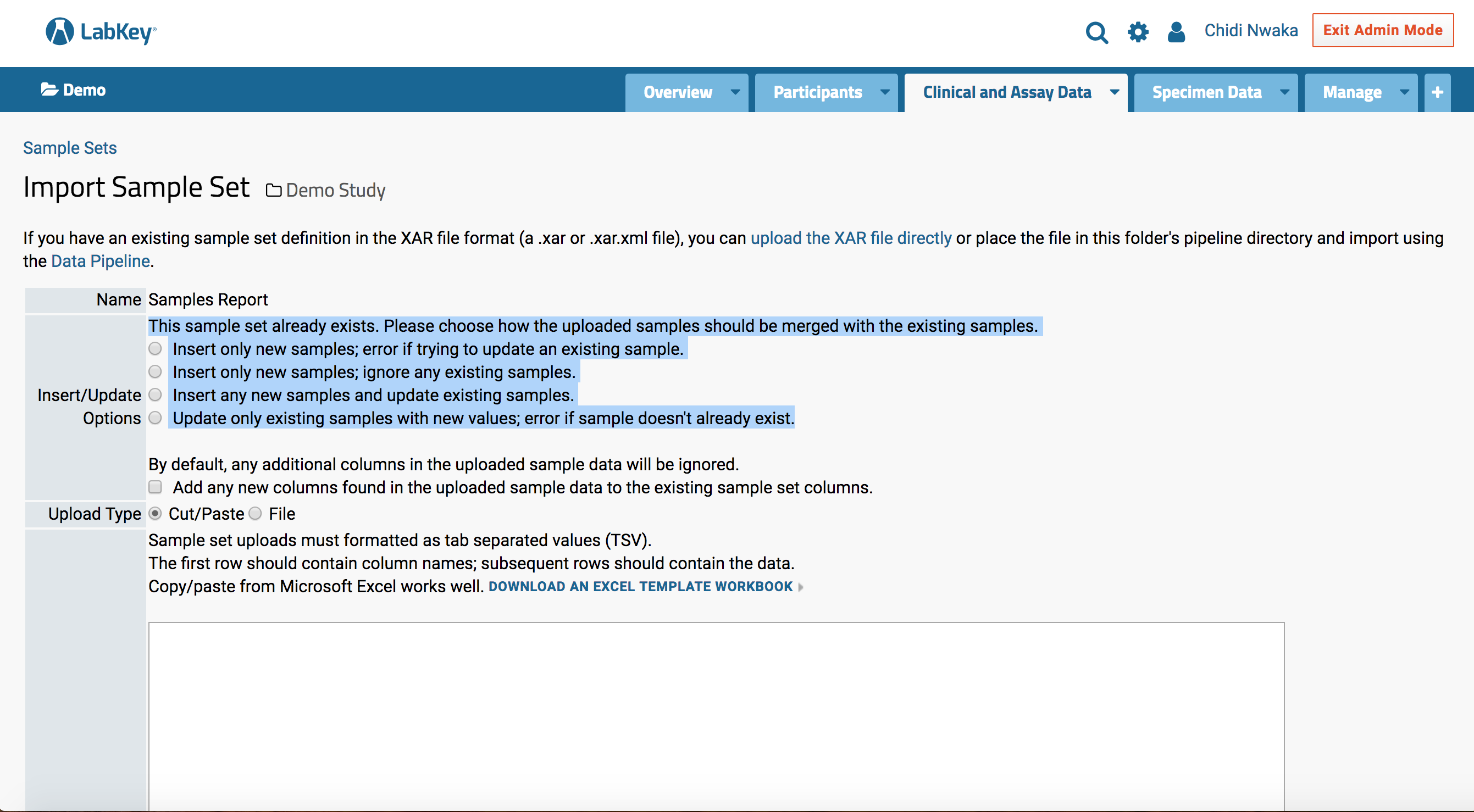 Screen Shot 2018-08-01 at 9.24.36 AM.png
Screen Shot 2018-08-01 at 9.24.36 AM.png Reagent-1.PNG
Reagent-1.PNG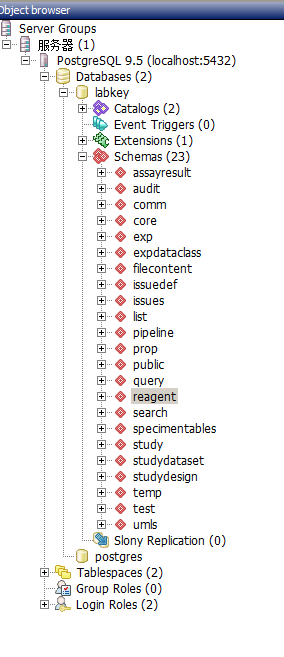 Reagent-2.PNG
Reagent-2.PNG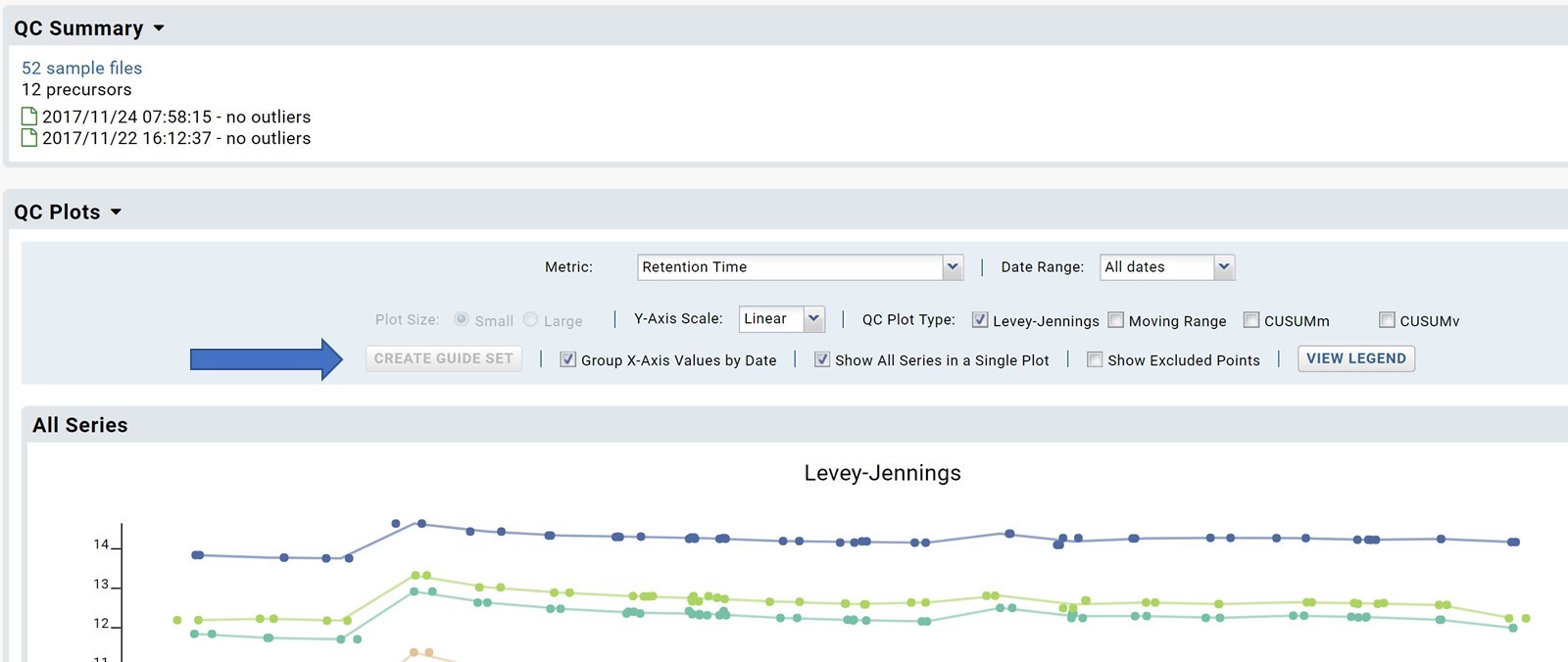 QC_Plot_Guide-Set-Gray-Out.jpg
QC_Plot_Guide-Set-Gray-Out.jpg Error1.JPG
Error1.JPG S1.png
S1.png S2.png
S2.png Skyline daily.png
Skyline daily.png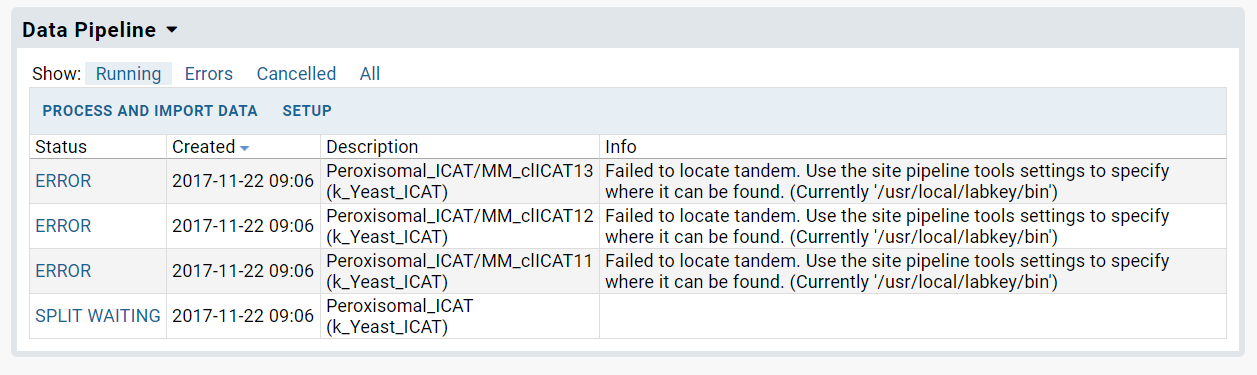 proteomics_tandem.png
proteomics_tandem.png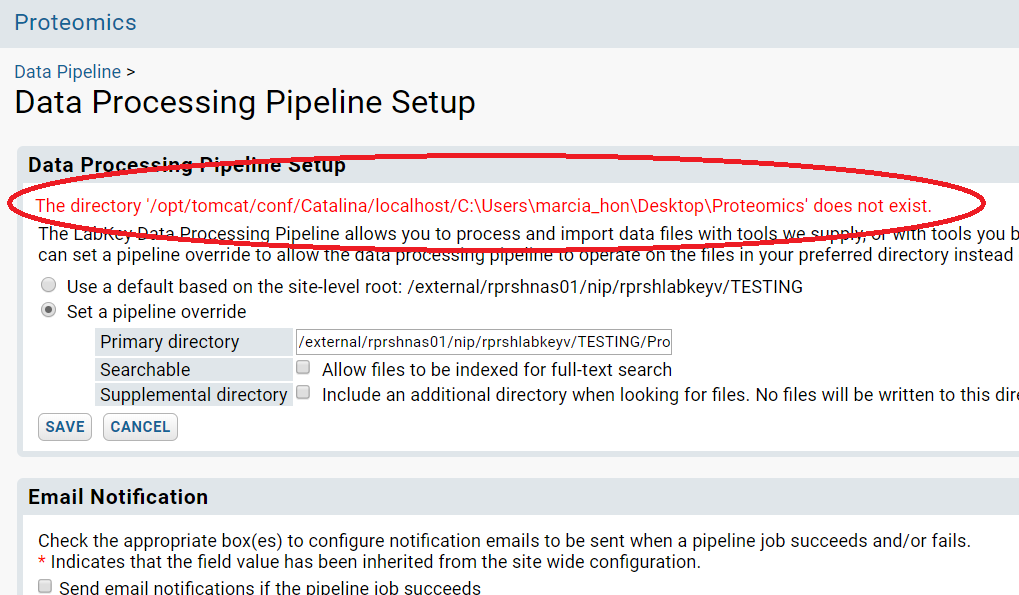 proteomics_pipeline.png
proteomics_pipeline.png